
世界模型这个词,快被用烂了。
视频生成模型说自己是世界模型,能生成游戏的语言模型也叫世界模型,还有人把物理引擎也塞进这个筐里……
李飞飞本人都看不下去了。
就在刚刚,她亲自撰文,给世界模型来了个清晰的功能分类。用词毫不客气:
"世界模型是当今AI领域最重要也最被滥用的术语之一。"
一、先搞清楚:世界模型到底干三件事
李飞飞说,古希腊人无法就世界的构成达成共识,因为"世界"从来不是一个单一的实体。
AI也继承了同样的问题。
但至少,要先分清三件事:渲染、模拟、规划。
这三件事,对应三种完全不同的能力。
二、渲染器:给你看的,不一定是真的
渲染器输出的是给人看的画面,核心指标是视觉保真度。
谷歌的Genie 3、李飞飞自家World Labs的RTFM,都属于渲染器。
这类模型生成的是观众看到的画面,而不是实际存在的画面。
什么意思?
AI生成的无人机航拍镜头里,建筑物从空中俯瞰可能完美无瑕。但你开车穿过那座城市,就会发现它们摇摇欲坠。
渲染器优化的是视觉逼真度,不是物理精确度。
它非常吸睛,但没法用来做建筑设计或机器人训练。
目前商业上最成熟的就是这一类,比如风靡全球的Nano Banana。
三、规划器:决定机器人该干什么
规划器输入观察和目标,输出下一步动作。
VLA模型和新一代世界动作模型都属于规划器,决定了机器人在非结构化世界中应该做什么。
这一块最吸引人,也最具发展潜力。大量热钱正在涌入。
但李飞飞泼了冷水:
近年来很多令人印象深刻的机器人演示,都局限于高度受限的实验室环境。 目标对象范围狭窄,任务周期短,根本没法在真实世界的复杂性下验证。
换句话说,别被演示视频骗了。
四、模拟器:最被低估的关键一环
模拟器输出可计算、可交互的状态,强调几何、物理、动态一致性。
它要求几何结构经得起检验,物理上符合定律,动力学行为符合世界运行方式。
模拟器同时服务两个群体:建筑师、设计师需要超越视觉逼真的精确度;强化学习和自动驾驶需要大规模训练场。
李飞飞认为,模拟是连接渲染和规划的桥梁。
如果说语言是对世界的抽象,像素是对世界的投影,那几何、物理和动力学就是世界本身。
模拟器正是视觉外观和动作后果得以生成的结构骨架。
商业前景极其广阔,英伟达的Omniverse平台瞄准的就是这个超万亿美元的市场。
但问题也很明显:能用来训练模拟器的数据太少了。具有明确几何形状、材料属性和物理标注的三维数据,比渲染器训练用的互联网视频少几个数量级。
五、三者正在融合,终点是一个统一的世界模型
李飞飞最关键的一个观点是:三类模型正在相互融合。
如果一个模型真正理解一个杯子是怎么放在桌子上的——几何结构、材料属性、受力反应——那它就应该能从任意角度渲染这个杯子,模拟杯子被推动时发生什么,并规划一只手怎么把它拿起来。
这三类能力,其实是同一种底层理解的三种投影。
近期研究已经证明,预训练视频渲染器可以作为联合世界预测和行动预测的骨干网络。
渲染器和规划器之间的桥梁正在搭起来:让同一个模型既想象接下来会发生什么,也想象接下来应该做什么。
逻辑终点,是一个统一的世界模型——
一个基础模型,既能渲染照片级真实的视图,也能生成物理准确的结构,还能规划行动序列。
核心挑战仍然是数据。渲染器有海量互联网视频,但模拟器和规划器严重缺乏3D资产和机器人演示数据。
但李飞飞很乐观:方向已经很清楚了。
三条本来相互独立的研究线索,如今各自驱动了数十亿美元级的产业。而现在,它们开始表现得像同一件事。
当它们的边界共同塌缩,机器智能和物理世界之间的关系,将被彻底重塑。
语言给了机器一种谈论世界的方式,而世界模型,将是机器最终理解、想象、推理并与世界互动的方式。
这就是空间智能的漫长弧线。
你觉得,统一的世界模型,多久能实现?
 哈佛最年轻教授尹希加盟OpenAI:AI几周干完我十年的活!
哈佛最年轻教授尹希加盟OpenAI:AI几周干完我十年的活!
 21岁CEO融资470万美金:AI Agent最大的问题,不是模型不够聪明
21岁CEO融资470万美金:AI Agent最大的问题,不是模型不够聪明
 奥尔特曼主动送股给美国政府:AI巨头为何甘愿"公私合营"?
奥尔特曼主动送股给美国政府:AI巨头为何甘愿"公私合营"?
 26岁白手起家成亿万富翁:800万人用他的产品,不用写一行代码
26岁白手起家成亿万富翁:800万人用他的产品,不用写一行代码
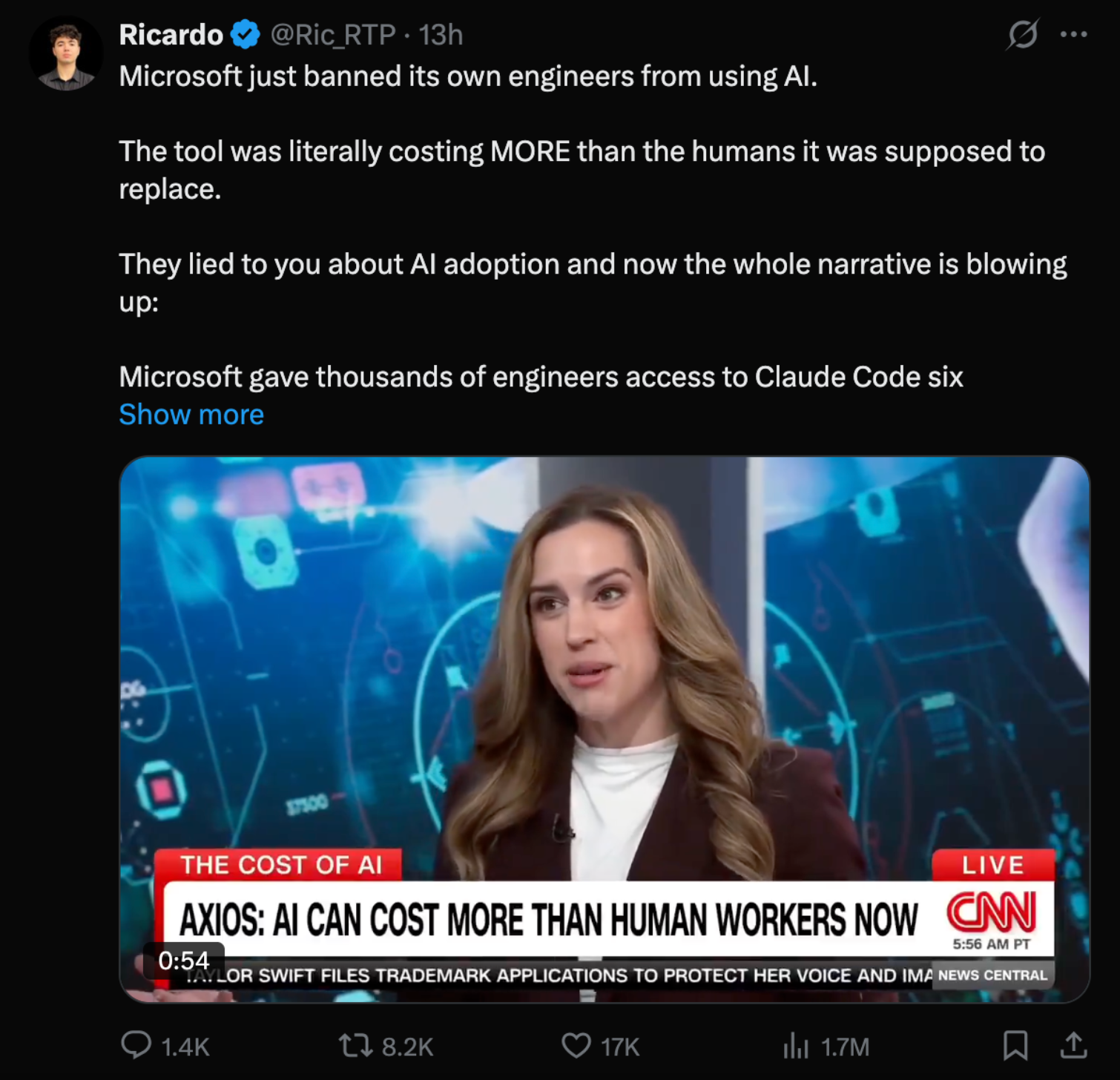 微软叫停内部Claude Code:一场"用不起"背后的三重困境!
微软叫停内部Claude Code:一场"用不起"背后的三重困境!
 SillyTavern角色卡:AI时代闷声发财的隐秘赛道,利润率超80%!
SillyTavern角色卡:AI时代闷声发财的隐秘赛道,利润率超80%!
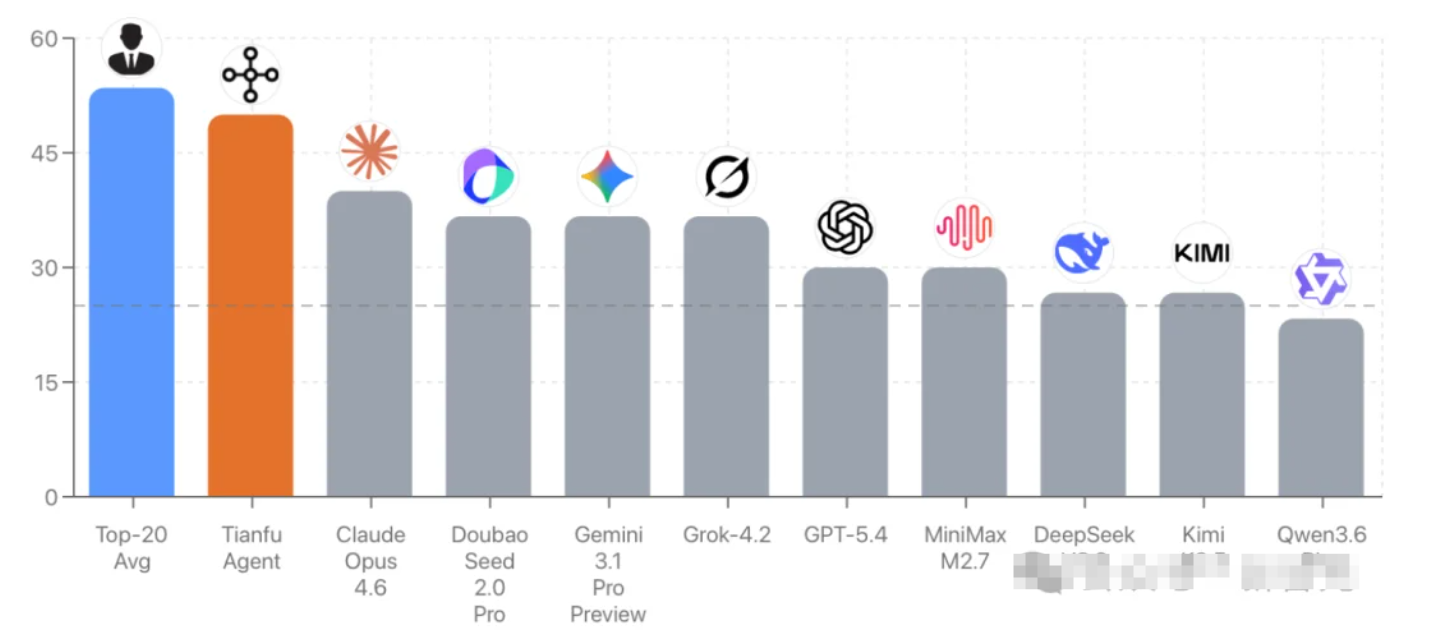 Tianfu Agent:200+工具让AI术数推理逼近人类大师水平!
Tianfu Agent:200+工具让AI术数推理逼近人类大师水平!
 天机智能完成10亿融资估值近百亿,具身力控双臂量产领跑全球!
天机智能完成10亿融资估值近百亿,具身力控双臂量产领跑全球!
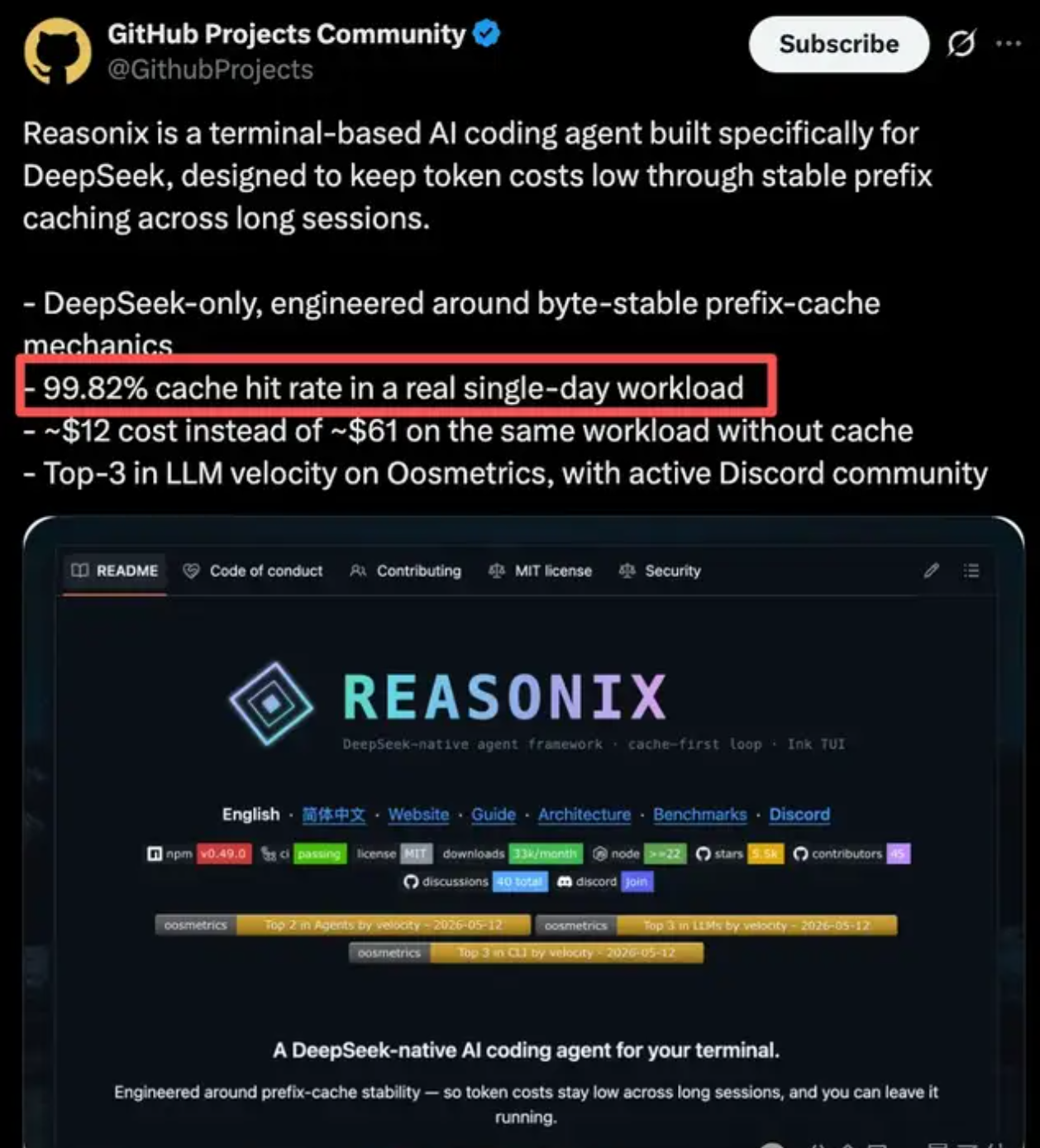 DeepSeek省钱神器Reasonix:缓存命中99.82%,4亿token账单直降80%!
DeepSeek省钱神器Reasonix:缓存命中99.82%,4亿token账单直降80%!
 Oracle XStream CDC实测:37000 TPS下性能影响全面评估!
Oracle XStream CDC实测:37000 TPS下性能影响全面评估!