Benchmark成绩是幻觉
过去一年,GUI Agent的评测分数一路飙升,"全自动办公"似乎触手可及。但UniPat AI用SaaS-Bench撕碎了这个幻觉:23个真实SaaS系统、106个任务、六大专业领域,全部在Docker中本地部署,保留完整的前后端逻辑和业务数据。93.4%的任务跨越至少两个应用,最长操作轨迹超300步。这才是真实办公的样子。
最强模型也"全军覆没"
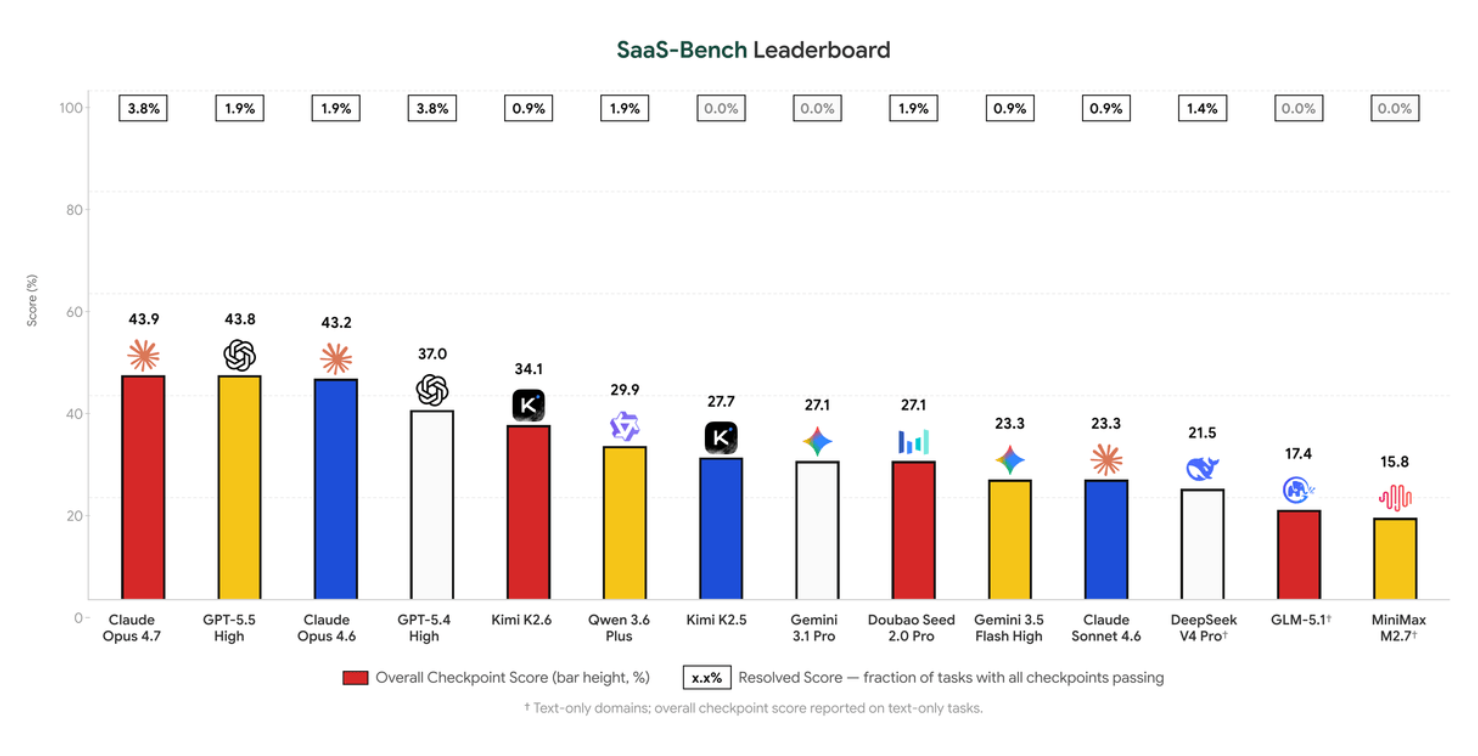
结果极其残酷。Claude Opus 4.7的检查点分数43.9%,端到端完全通过分数仅3.8%——106个任务只完整走完4个。Kimi K2.5和Gemini 3.1 Pro的完全通过分数为零。Agent能推进部分中间环节,但几乎没有能力将完整长程工作流走完。多跑三次提升约8个百分点,但远非解决方案。
四种结构性失败
SaaS-Bench暴露了Agent的四大致命缺陷。第一,任务越长越做不对,通过率随执行呈不可逆下降曲线。第二,一步错步步错——一个3%权重的错误节点导致下游30%的分数损失。第三,做完不检查,Agent在意图层面认为成功,验证器在状态层面发现失败,缺少严谨的反思闭环。第四,同一任务三次运行分数从0到0.68剧烈波动,路径依赖让长程执行变成赌博。
底层问题
这四种失败指向同一个事实:当前Agent缺少对持久状态的有效推理能力,缺少操作后的闭环验证机制,缺少从错误中恢复的能力。这不是模型变大或加几个工程模块能解决的,而是当前范式的天花板——模型无法像人一样"心里有数"。
SaaS要为Agent重做
SaaS-Bench揭示的不只是Agent的短板,也是当前软件形态的保质期。今天的SaaS为人类设计——菜单、按钮、表单服务于人的眼睛和手指。但当Agent成为主要用户,这些界面就变成累赘。未来不是让Agent学会操作人类的软件,而是软件本身要为Agent重新设计。
 李飞飞亲自下场:世界模型到底是什么?一句话说清楚了
李飞飞亲自下场:世界模型到底是什么?一句话说清楚了
 李沐团队发布语音模型新杀器:111种语言、零样本克隆、实时对话!
李沐团队发布语音模型新杀器:111种语言、零样本克隆、实时对话!
 微软叫停内部Claude Code:一场"用不起"背后的三重困境!
微软叫停内部Claude Code:一场"用不起"背后的三重困境!
 Oracle XStream CDC实测:37000 TPS下性能影响全面评估!
Oracle XStream CDC实测:37000 TPS下性能影响全面评估!
 SaaS-Bench实测23个真系统:最强AI Agent仅完整通过4个任务!
SaaS-Bench实测23个真系统:最强AI Agent仅完整通过4个任务!
 4个AI无法律小镇15天:一个4天灭绝,一个主动自杀
4个AI无法律小镇15天:一个4天灭绝,一个主动自杀
 Waymo无人车再陷积水困境,特斯拉FSD却越开越像老司机!
Waymo无人车再陷积水困境,特斯拉FSD却越开越像老司机!
 奥尔特曼主动送股给美国政府:AI巨头为何甘愿"公私合营"?
奥尔特曼主动送股给美国政府:AI巨头为何甘愿"公私合营"?
 21岁CEO融资470万美金:AI Agent最大的问题,不是模型不够聪明
21岁CEO融资470万美金:AI Agent最大的问题,不是模型不够聪明
 GPT-5.5被实锤"降智":200美元买的旗舰模型,背后偷偷换成了mini!
GPT-5.5被实锤"降智":200美元买的旗舰模型,背后偷偷换成了mini!